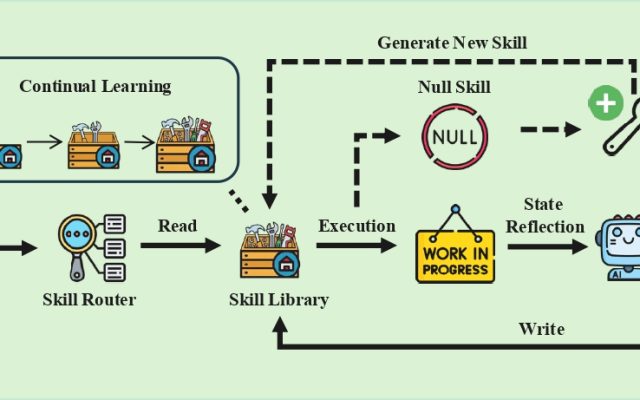
Block’s Managerbot: The Proactive AI Agent That Predicts Problems Before Small Business Owners Do
Block has unveiled Managerbot, a new AI agent embedded in the Square platform that proactively monitors a seller's business, identifies emerging problems, and proposes actionable solutions—without the seller ever having to ask…